Overview and getting started#
Examples#
We have various example scripts and notebooks for using ipyparallel in our
docs/source/examples directory, as covered in the examples section.
Introduction#
This section gives an overview of IPython’s architecture for parallel and distributed computing. This architecture abstracts out parallelism in a general way, enabling IPython to support many different styles of parallelism, including:
Single program, multiple data (SPMD) parallelism
Multiple program, multiple data (MPMD) parallelism
Message passing using MPI
Task farming
Data parallel
Combinations of these approaches
Custom user-defined approaches
Most importantly, IPython enables all types of parallel applications to
be developed, executed, debugged, and monitored interactively. Hence,
the I in IPython. The following are some example use cases for IPython:
Quickly parallelize algorithms that are embarrassingly parallel using a number of simple approaches. Many simple things can be parallelized interactively in one or two lines of code.
Steer traditional MPI applications on a supercomputer from an IPython session on your laptop.
Analyze and visualize large datasets (that could be remote and/or distributed) interactively using IPython and tools like matplotlib.
Develop, test and debug new parallel algorithms (that may use MPI) interactively.
Tie together multiple MPI jobs running on different systems into one giant distributed and parallel system.
Start a parallel job on your cluster and then have a remote collaborator connect to it and pull back data into their local IPython session for plotting and analysis.
Run a set of tasks on a set of CPUs using dynamic load balancing.
Tip
At the SciPy 2014 conference in Austin, Min Ragan-Kelley presented a complete 4-hour tutorial on the use of these features, and all the materials for the tutorial are now available online. That tutorial provides an excellent, hands-on oriented complement to the reference documentation presented here.
Architecture overview#
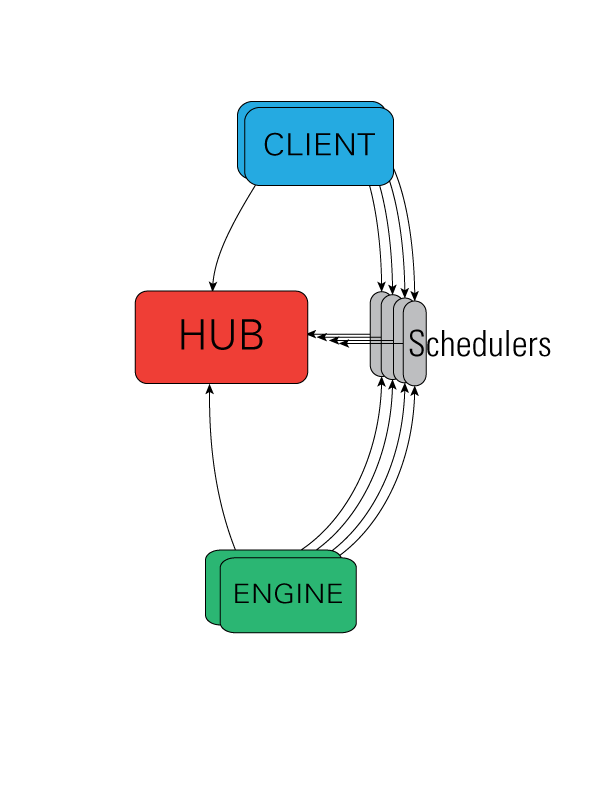
The IPython architecture consists of four components:
The IPython engine
The IPython hub
The IPython schedulers
The IPython client
These components live in the ipyparallel package,
which can be installed with pip or conda.
IPython engine#
The IPython engine is an extension of the IPython kernel for Jupyter. The engine listens for requests over the network, runs code, and returns results. IPython parallel extends the Jupyter messaging protocol to support native Python object serialization and add some additional commands. When multiple engines are started, parallel and distributed computing becomes possible.
IPython controller#
The IPython controller processes provide an interface for working with a set of engines.
At a general level, the controller is a collection of processes to which IPython engines
and clients can connect. The controller is composed of a Hub and a collection of
Schedulers. These Schedulers are typically run in separate processes on the
same machine as the Hub.
The controller also provides a single point of contact for users who wish to
access the engines connected to the controller. There are different ways of
working with a controller. In IPython, all of these models are implemented via
the View.apply() method, after
constructing View objects to represent subsets of engines. The two
primary models for interacting with engines are:
A Direct interface, where engines are addressed explicitly
A LoadBalanced interface, where the Scheduler is entrusted with assigning work to appropriate engines
Advanced users can readily extend the View models to enable other styles of parallelism.
Note
A single controller and set of engines can be used with multiple models simultaneously. This opens the door for lots of interesting things.
The Hub#
The center of an IPython cluster is the Hub. This is the process that keeps track of engine connections, schedulers, clients, as well as all task requests and results. The primary role of the Hub is to facilitate queries of the cluster state, and minimize the necessary information required to establish the many connections involved in connecting new clients and engines.
Schedulers#
All actions that can be performed on the engine go through a Scheduler. While the engines themselves block when user code is run, the schedulers hide that from the user to provide a fully asynchronous interface to a set of engines.
IPython client and views#
There is one primary object, the Client, for connecting to a cluster.
For each execution model, there is a corresponding View. These views
allow users to interact with a set of engines through the interface. Here are the two default
views:
The
DirectViewclass for explicit addressing.The
LoadBalancedViewclass for destination-agnostic scheduling.
Getting Started#
To use IPython for parallel computing, you need to start one instance of the controller and one or more instances of the engine. Initially, it is best to start a controller and engines on a single host. To start a controller and 4 engines on your local machine:
In [1]: import ipyparallel as ipp
In [2]: cluster = ipp.Cluster(n=4)
In [3]: await cluster.start_cluster() # or cluster.start_cluster_sync() without await
Note
Most Cluster methods are async,
and all async cluster methods have a blocking version with a _sync suffix,
e.g. await cluster.start_cluster() and cluster.start_cluster_sync()
You can also launch clusters at the command-line with:
$ ipcluster start -n 4
which is equivalent to ipp.Cluster(n=4, cluster_id="").start_cluster()
and connect to the already-running cluster with Cluster.from_file()
cluster = ipp.Cluster.from_file()
For a convenient one-liner to start a cluster and connect a client,
use start_and_connect_sync():
In [1]: import ipyparallel as ipp
In [2]: rc = ipp.Cluster(n=4).start_and_connect_sync()
More details about starting the IPython controller and engines can be found here.
Once you have a handle on a cluster, you can connect a client. To make sure everything is working correctly, try the following commands:
In [2]: rc = cluster.connect_client_sync()
In [3]: rc.wait_for_engines(n=4)
In [4]: rc.ids
Out[4]: [0, 1, 2, 3]
In [5]: rc[:].apply_sync(lambda: "Hello, World")
Out[5]: [ 'Hello, World', 'Hello, World', 'Hello, World', 'Hello, World' ]
When a client is created with no arguments, the client tries to find the corresponding JSON file
in the local ~/.ipython/profile_default/security directory. Or if you specified a profile,
you can use that with the Client. This should cover most cases:
In [2]: cluster = ipp.Cluster.from_file(profile="myprofile", cluster_id="...")
In [3]: rc = cluster.connect_client_sync()
If you have put the JSON file in a different location or it has a different name, create the Cluster object like this:
In [2]: cluster = ipp.Cluster.from_file('/path/to/my/cluster-.json')
Remember, a client needs to be able to see the Hub’s ports to connect. So if the controller and client are on different machines, you may need to use an ssh server to tunnel access to that machine, in which case you would connect with:
In [2]: c = ipp.Client('/path/to/my/ipcontroller-client.json', sshserver='me@myhub.example.com')
Where ‘myhub.example.com’ is the url or hostname of the machine on which the Hub process is running (or another machine that has direct access to the Hub’s ports).
The SSH server may already be specified in ipcontroller-client.json, if the controller was instructed at its launch time.
Cluster as context manager#
The Cluster and Client classes can be used as context managers
for easier cleanup of resources.
Entering a
Clustercontextstarts the cluster
waits for engines to be ready
connects a client
returns the client
Exiting a
Clientcontext closes the client’s socket connections to the cluster.Exiting a
Clustercontext shuts down all of the cluster’s resources.
If you know you won’t need your cluster anymore after you use it, use of these context managers is encouraged. For example:
import ipyparallel as ipp
# start cluster, connect client
with ipp.Cluster(n=4) as rc:
e_all = rc[:]
ar = e_all.apply_sync(task)
ar.wait_interactive()
results = ar.get()
# have results, cluster is shutdown
You are now ready to learn more about the Direct and LoadBalanced interfaces to the controller.