Broadcast View#
IPython Parallel is built on the idea of working with N remote IPython instances. This means that most of the ‘parallelism’ when working with N engines via the DirectView is really implemented in the client.
DirectView methods are all implemented as:
for engine in engines:
do_something_on(engine)
which means that all operations are at least O(N) at the client. This can be really inefficient when the client is telling all the engines to do the same thing, especially when the client is across the Internet from the cluster.
IPython 7 includes a new, experimental broadcast scheduler that implements the same message pattern, but sending a request to any number of engines is O(1) in the client. It is the scheduler that implements the fan-out to engines.
With the broadcast view, a client always sends one message to the root node of the scheduler. The scheduler then sends one message to each of its two branches, and so on until it reaches the leaves of the tree, at which point each leaf sends $\frac{N}{2^{depth}}$ messages to its assigned engines.
The performance should be strictly better with a depth of 0 (one scheduler node), network-wise, though the Python implementation of the scheduler may have a cost relative to the pure-C default DirectView scheduler.
This approach allows deplyments to exchange single-message latency (due to increased depth) for parallelism (due to concurrent sends at the leaves).
This trade-off increases the baseline cost for small numbers of engines, while dramatically improving the total time to deliver messages to large numbers of engines, especially when they contain a lot of data.
These tests were run with a depth of 3 (8 leaf nodes)
import ipyparallel as ipp
rc = ipp.Client(profile="mpi")
rc.wait_for_engines(100)
direct_view = rc.direct_view()
bcast_view = rc.broadcast_view()
/Users/minrk/dev/ip/parallel/ipyparallel/util.py:205: RuntimeWarning: IPython could not determine IPs for ip-172-31-2-77: [Errno 8] nodename nor servname provided, or not known
warnings.warn(
print(f"I have {len(rc)} engines")
I have 100 engines
To test baseline latency, we can run an empty apply task with both views:
%timeit direct_view.apply_sync(lambda: None)
311 ms ± 67.3 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit bcast_view.apply_sync(lambda: None)
259 ms ± 14.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
With 100 engines, it takes noticeably longer to complete on the direct view as the new broadcast view.
Sending the same data to engines is probably the pattern that most suffers from this design, because identical data is duplicated once per engine in the client.
We can compare view.push with increasing array sizes:
import numpy as np
dview_times = []
bcast_times = []
n_list = [16, 64, 256, 512]
for n in n_list:
chunk = np.random.random((n, n))
b = chunk.nbytes
unit = 'B'
if b > 1024:
b //= 1024
unit = 'kB'
if b > 1024:
b //= 1024
unit = 'MB'
print(f"{n:4} x {n:4}: {b:4} {unit}")
print("Direct view")
tr = %timeit -o -n 1 direct_view.push({"chunk": chunk}, block=True)
dview_times.append(tr.average)
print("Broadcast view")
tr = %timeit -o -n 1 bcast_view.push({"chunk": chunk}, block=True)
bcast_times.append(tr.average)
16 x 16: 2 kB
Direct view
287 ms ± 72 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Broadcast view
266 ms ± 10.5 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
64 x 64: 32 kB
Direct view
598 ms ± 62.2 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Broadcast view
274 ms ± 30.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
256 x 256: 512 kB
Direct view
5.99 s ± 199 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Broadcast view
297 ms ± 43.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
512 x 512: 2 MB
Direct view
22.9 s ± 428 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Broadcast view
559 ms ± 107 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
import matplotlib.pyplot as plt
import pandas as pd
df = pd.DataFrame({"n": n_list, "direct view": dview_times, "broadcast": bcast_times})
df["broadcast speedup"] = df["direct view"] / df.broadcast
# MB is the total number of megabytes delivered (n * n * 8 * number of engines bytes)
df["MB"] = df["n"] ** 2 * 8 * len(rc) / (1024 * 1024)
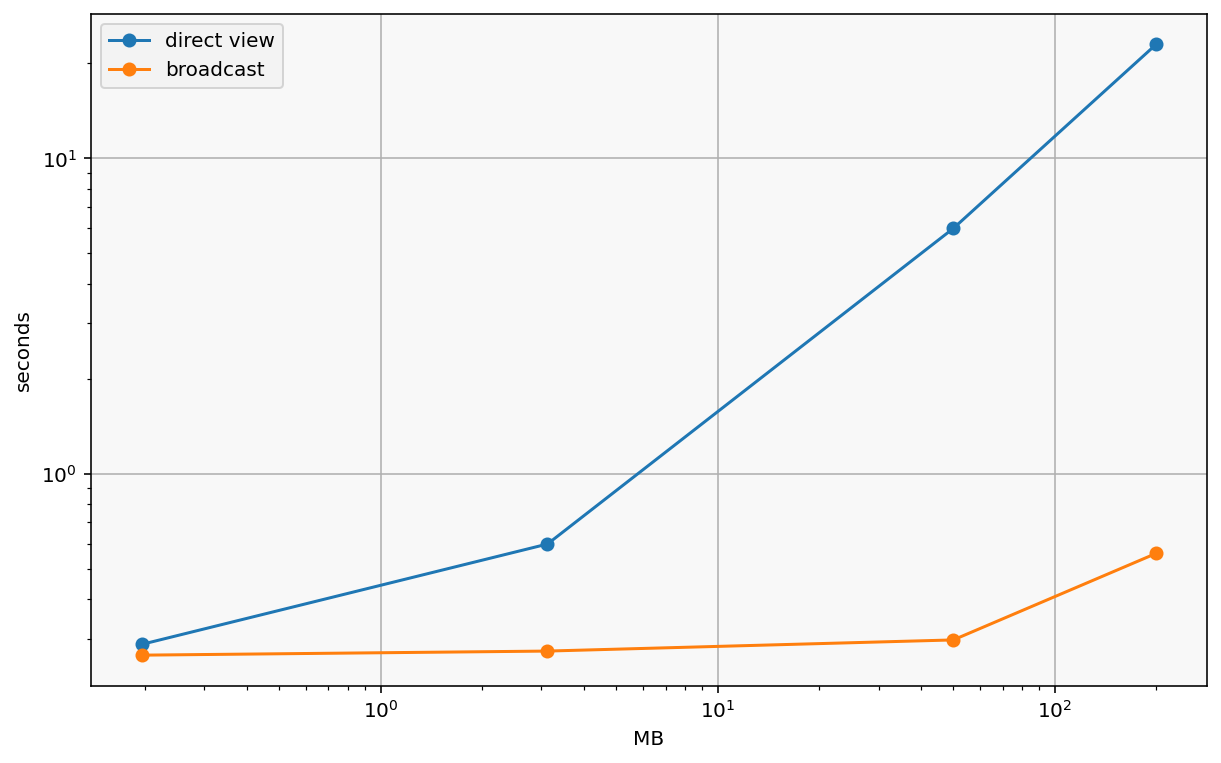
df
| n | direct view | broadcast | broadcast speedup | MB | |
|---|---|---|---|---|---|
| 0 | 16 | 0.287495 | 0.265786 | 1.081679 | 0.195312 |
| 1 | 64 | 0.598065 | 0.273835 | 2.184031 | 3.125000 |
| 2 | 256 | 5.986274 | 0.297034 | 20.153521 | 50.000000 |
| 3 | 512 | 22.946806 | 0.558653 | 41.075245 | 200.000000 |
df.plot(x='MB', y=['direct view', 'broadcast'], style='-o', loglog=True)
plt.ylabel("seconds")
Text(0, 0.5, 'seconds')
Tuning broadcast views#
As mentioned above, depth is a tuning parameter to exchange latency for parallelism.
This can be set with IPController.broadcast_scheduler_depth configuration (default: 1).
The number of leaf nodes in the tree is 2^d where d is the depth of the tree ($d=0$ means only a root node).
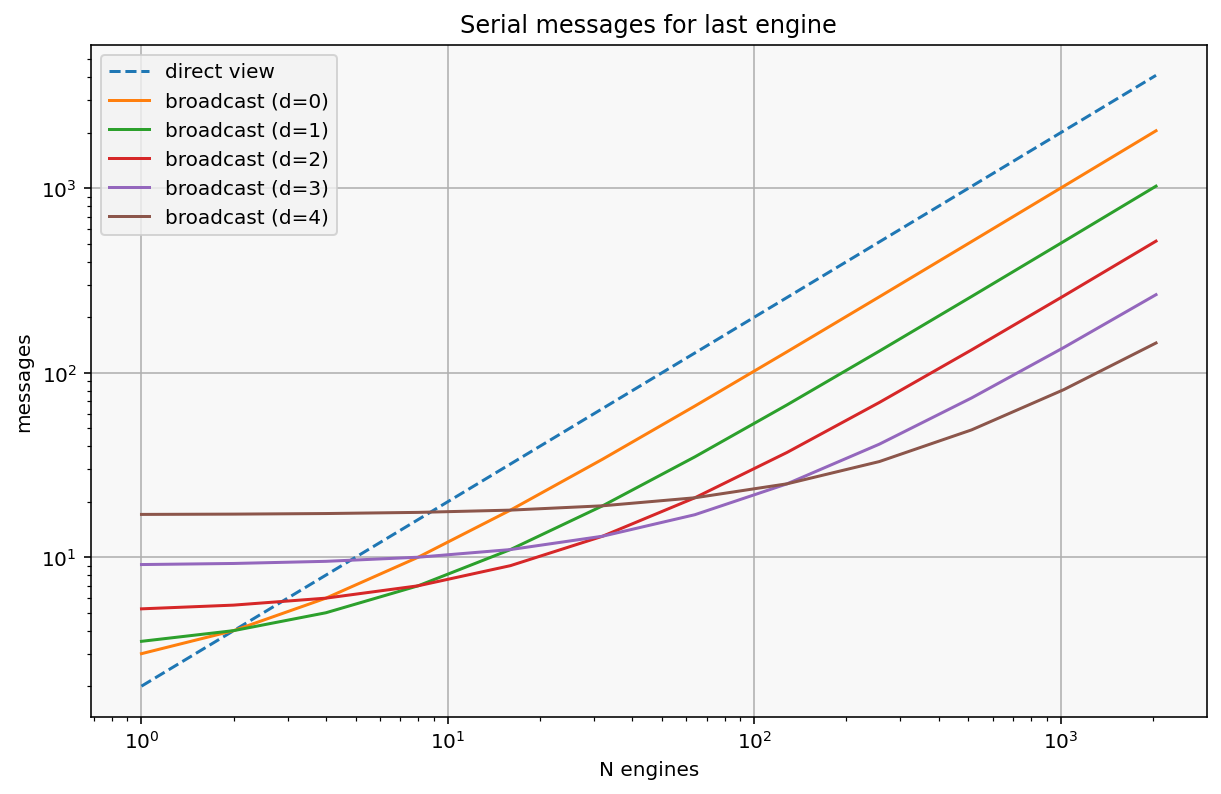
With a DirectView, the total number of request messages is $ 2 N $ and the number of requests to deliver the first message is 2 (one client->scheduler, one scheduler->engine).
With a Broadcast View, the total number of request messages is
$$ N + 1 + \sum_{i=1}^{d} 2^i $$
Since we are talking about delivering messages to all engines, the metric of interest for a ‘cold start’ is how many messages must the last engine wait for before its message is delivered, because until that point, at least some of the cluster is idle, waiting for a task. This is where the parallelism comes into play.
In the DirectView, the message destined for the last engine N must wait for N sends from the client to the scheduler, then again for N sends from the scheduler to each engines, for a total of 2 N sends before the engines gets its message.
In the BroadcastView, we only have to count sends along one path down the tree:
one send at the client
two sends at each level of the scheduler
$\frac{N}/{2^d}$ sends at the leaf of the scheduler
for a total of:
$$ 1 + 2^d + \frac{N}{2^d} $$
sends to get the first message to the last engine (and therefore all engines). This is a good approximation of how deep your scheduler should be based on the number of engines. It is an approximation because it doesn’t take into account the difference in cost between a local zmq send call vs a send actually traversing the network and being received.
import numpy as np
N = np.logspace(0, 11, 12, base=2, dtype=int)
N
dview_sends = 2 * N
def bcast_sends(N, depth):
return 1 + (2**depth) + (N / (2**depth))
plt.loglog(N, dview_sends, '--', label="direct view")
for depth in range(5):
plt.loglog(N, bcast_sends(N, depth), label=f"broadcast (d={depth})")
plt.xlabel("N engines")
plt.ylabel("messages")
plt.title("Serial messages for last engine")
plt.grid(True)
plt.legend(loc=0)
<matplotlib.legend.Legend at 0x7f97d28e4cd0>
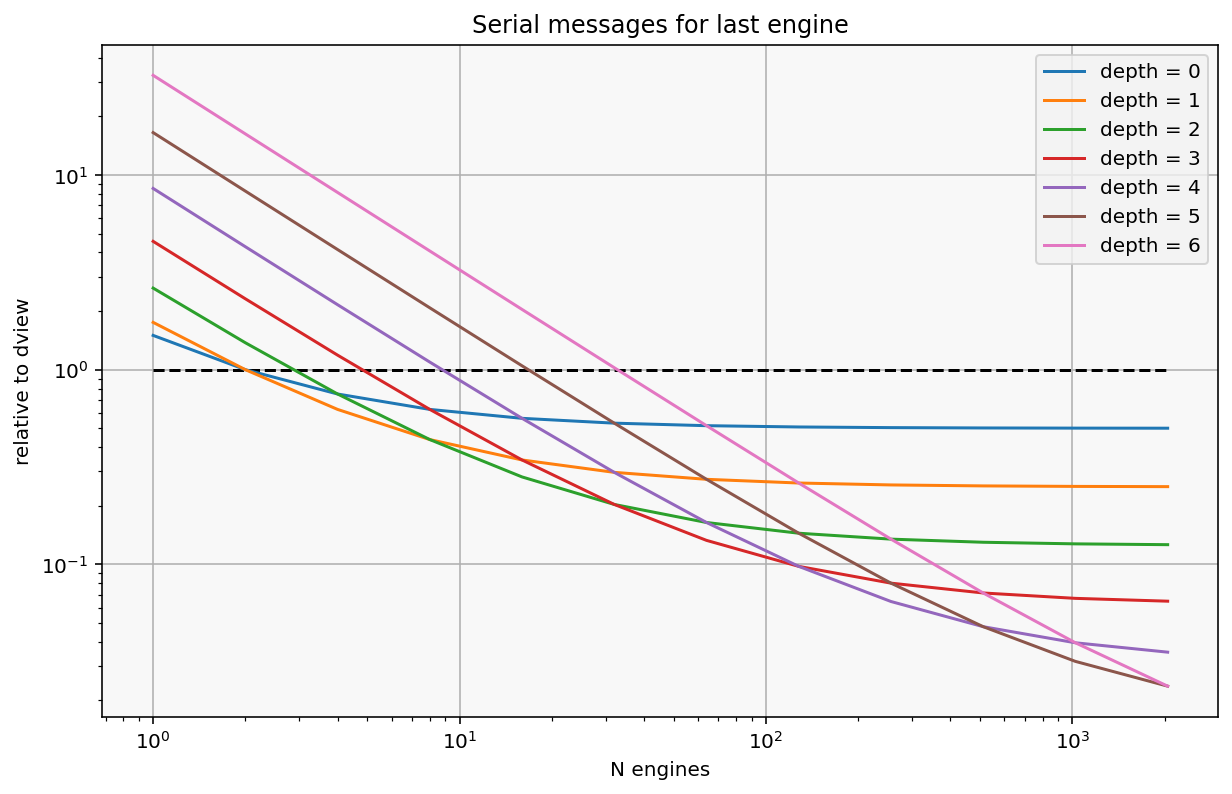
# <!-- plt.semilogx(N, dview_sends, '--', label="direct view") -->
plt.plot(N, [1] * len(N), '--k')
for depth in range(7):
plt.loglog(N, bcast_sends(N, depth) / dview_sends, label=f"depth = {depth}")
plt.xlabel("N engines")
plt.ylabel("relative to dview")
plt.title("Serial messages for last engine")
plt.grid(True)
plt.legend(loc=0)
<matplotlib.legend.Legend at 0x7f97d2f91640>
Coalescing replies#
The broadcast view changes the number of requests a client sends from one per engine to just one, however each engine still has its own reply to that request.
One of the sources of performance in the client, especially when sending many small tasks, is contention receiving replies.
The IPython Parallel client receives replies in a background thread. If replies start arriving before the client is done sending requests, this can result in a lot of contention and context switching, slowing down task submission.
Plus, deserializing all these replies can be a lot of work, especially if the only useful information is that it’s done.
For this, the broadcast view has a tuning parameter to ‘coalesce’ replies. Unlike depth, this parameter is set per-request instead of for the cluster as a whole.
Coalescing reduces the number of replies in the same way that requests are reduced on the way to engines - by collecting replies at each node, and only sending them along to the next layer up when all engines have replied.
As a result, when coalescing is enabled, a BroadcastView sends exactly one request and receives exactly one reply, dramatically reducing the workload and number of events on the client.
bcast_view.is_coalescing = False
%timeit bcast_view.apply_sync(lambda: None)
288 ms ± 44 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
bcast_view.is_coalescing = True
%timeit bcast_view.apply_sync(lambda: None)
216 ms ± 26.4 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Coalescing has its own trade-offs. Each send and receive at each level has a cost, but so does waiting to send messages. Coalescing behaves best when lots of (especially small) replies are going to come at the same time. If responses are large and/or spread out, the cost of leaving network bandwidth idle will outweigh the savings of reduced message deserialization.